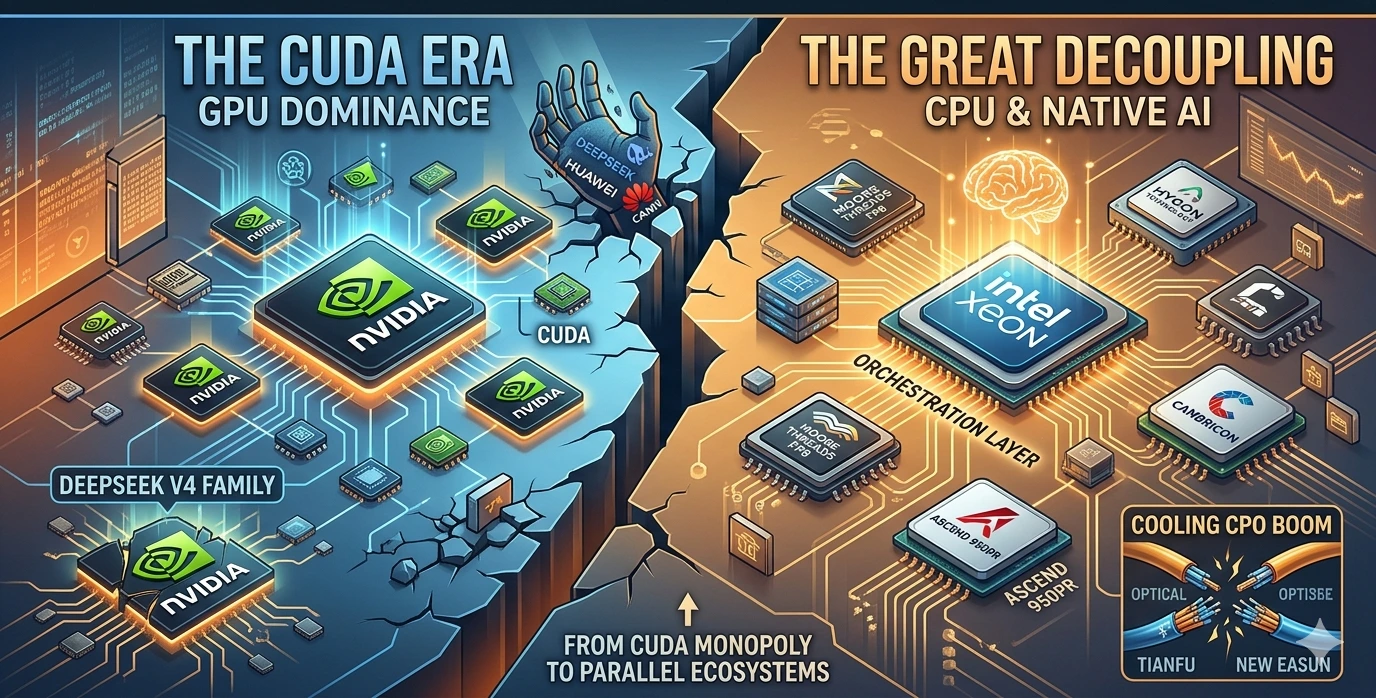
The AI landscape didn’t just shift on April 24, 2026, it underwent a structural realignment. Between the release of DeepSeek’s V4 family and a blockbuster quarterly report from Intel, the industry is witnessing the “Great Decoupling”: a move away from the NVIDIA CUDA monopoly and a surprising return to the CPU as a central pillar of the AI stack.
DeepSeek, the Chinese AI powerhouse, chose April 24 to unveil its most ambitious project to date: the DeepSeek V4 family. The release isn’t just another benchmark-chasing iteration; it is a calculated “geopolitical statement.” For the first time, a frontier-class model has successfully migrated its underlying code from the ubiquitous NVIDIA CUDA ecosystem to Huawei’s CANN (Compute Architecture for Neural Networks) framework.
The implications are staggering. By completing the entire training and inference chain adaptation on Huawei’s Ascend 950PR chips, DeepSeek has effectively neutralized the impact of Western export controls. As NVIDIA CEO Jensen Huang noted in a recent podcast, a world where high-tier models run natively on non-NVIDIA silicon is a “terrible outcome” for the traditional market status quo.
Inside the Beast: V4-Pro by the Numbers
DeepSeek V4 is structured as a two-tier lineup, catering to both maximalist reasoning and high-speed efficiency:
- DeepSeek V4-Pro: A 1.6 trillion parameter behemoth (with 49 billion active parameters at any given time).
- DeepSeek V4-Flash: A 284 billion parameter model (13 billion active) designed for high-throughput tasks.
- The “Million-Token” Window: Both models support a context length of 1 million tokens, allowing entire codebases or library-length documents to be processed in a single pass.
- Architectural Efficiency: Utilizing a Hybrid Mixture-of-Experts (MoE) design, V4 achieves a 73% reduction in per-token inference FLOPs and a 90% reduction in KV cache memory burden compared to its predecessor, V3.2.
The CPU Renaissance: Intel’s Revenge
While the GPU has been the undisputed king of the AI boom, Intel’s Q1 2026 financial report suggests a “return to the throne” for the Central Processing Unit. Across the Pacific, Intel reported $13.6 billion in revenue, a 7% year-on-year increase that crushed Wall Street expectations.
Most tellingly, Intel’s Data Center and AI business surged by 22% to $5.1 billion. Intel CEO Chen Liwu stated that the CPU is re-establishing its indispensable position as the “orchestration layer” and the key control plane for the entire AI stack.
“The first phase of the AI boom was driven by raw GPU horsepower,” Chen remarked. “The second phase is about orchestration, scaling, and efficiency—domains where the Xeon CPU is proving to be the fundamental bottleneck-breaker.”
This “CPU as the brain” narrative acted as a shot of adrenaline for domestic Chinese CPU manufacturers. Following the Intel report and the DeepSeek launch, A-share companies like Hygon Technology saw stock surges of over 10%, with Cambricon and Loongson following in their wake.
A-Share Pivot: Is the CPO Era Cooling Down?
For the past year, CPO (Co-packaged Optics) was the darling of the A-share market. However, recent first-quarter reports from industry leaders Tianfu Communication and New Easun (Xin Yisheng) have signaled a cooling period.
While revenue growth remains impressive (New Easun reported over 100% YoY growth), net profits saw a quarter-on-quarter decline, leading to market anxiety about the sustainability of the “optical” boom. As capital rotates, the theme for the coming week appears to be shifting from the interconnects (CPO) to the core compute (CPU/GPU).
Native Precision: The Moore Threads Advantage
A critical technical highlight of DeepSeek V4 is its use of a hybrid precision strategy: FP4 + FP8. This “native precision” approach allows for massive models to run with significantly less memory bandwidth.
Enter Moore Threads. Their flagship MTT S5000 GPU became one of the first domestic chips to achieve “Day-0” rapid adaptation for DeepSeek-V4-Flash. Because the MTT S5000 natively supports FP8 hardware-level acceleration, it can halve data bit width compared to traditional BF16, effectively doubling computational throughput.
In optimization tests with the FlagOS community, Moore Threads reported:
- 16.5% reduction in Time-to-First-Token (TTFT) latency.
- 65.7% improvement in overall throughput via automated kernel tuning.
The Verdict: A Parallel Ecosystem
The events of April 24 confirm that we are no longer looking at a single, global AI roadmap. We are witnessing the birth of a parallel hardware ecosystem.
DeepSeek has proven that 1.6-trillion-parameter models don’t need CUDA to breathe. Intel has proven that the CPU is not a legacy component, but an AI orchestrator. And the Chinese domestic chip market has proven it can move from “adaptation” to “optimization” in a matter of hours.
Next week, as the markets digest these shifts, all eyes will be on whether the “CPU + NATIVE AI” theme can sustain its momentum and permanently unseat the interconnect-heavy narratives of 2025.
Is your portfolio ready for the “Great Decoupling”, or are you still betting on a single-vendor future?